
기사 잘쓰는 GPT-3, '가짜뉴스 만드는' GPT-2와 무엇이 달라졌을까
언어모델의 경쟁구도가 BERT와 GPT-3의 대결로 압축이 되는 흐름입니다. BERT의 우위로 굳어지던 분위기가 GPT-3의 등장으로 다시 역전이 됐습니다.
제가 표지 포함 72페이지나 되는 공학계 영어 논문을 모두 이해했다는 건 거짓말일 겁니다. 이해하기 위해 애썼다는 말을 넘어서면 과장일 겁니다. 제가 이해한 만큼만 썼으니 정확한 내용은 저보다 더 훌륭한 분께 재확인하시길 부탁드립니다.
이 글을 읽기에 앞서 GPT-2 모델을 소개한 제 글을 먼저 읽어주시면 감사하겠습니다. 사전 이해가 필요한 개념들이 뒤섞여 있어서요.
GPT-2와 GPT-3는 무엇이 달라졌나
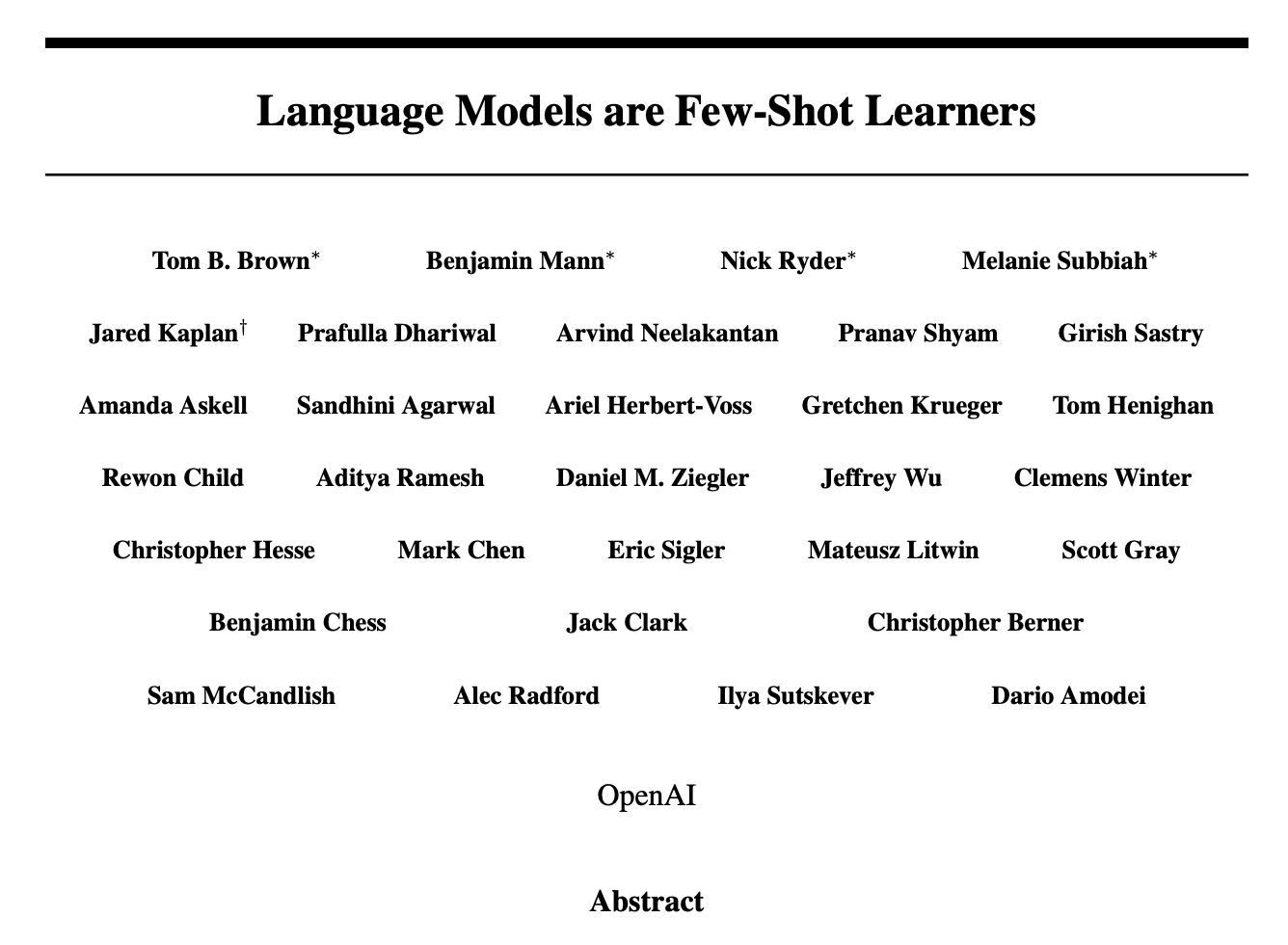
GPT-2 모델이 소개됐을 때 국내 언론들은 “가짜뉴스 만드는 AI”라는 제목을 달고 조명했습니다. 이번 모델도 그 관점에서 본다면, 대단한 성능을 발휘하는 모델이라고 볼 수 있을 겁니다. 이를테면, 테스트 대상이 된 모델 가운데 가장 거대한 모델인 GPT-3 175B(1750억 개 파라미터)은 사실상 사람조차도 구분 못할 정도의 뉴스를 만들어냈다고 평가할 수 있을 겁니다.
GPT-3 175B가 제작한 뉴스를 사람에게 보여줬을 때 평균 정답률(the ratio of correct assignment to non-neutral assignment)은 52%였습니다. 2개를 놓고 기계가 작성한 것인지 인간이 작성한 것인지 맞히는 게임에서 52%가 나왔다는 건 사실상 구분을 못했다는 의미와 다르지 않을 겁니다. 그만큼 기계와 인간이 제작한 뉴스 간의 품질 차이는 거의 사라졌다고 보시면 될 것입니다.
200단어 이하의 기사일 때, 500단어 이하의 기사일 때 평균 정답률도 52%로 차이가 없었습니다. 기억하실지 모르겠지만 쿼츠 커브를 떠올려 보시기 바랍니다. 사람들이 많이 읽는 기사의 길이는 500단어 이하이거나 800단어 이상이었죠. 적어도 500단어 이하 단문 중심의 스트레이트성 기사는 기계가 넘겨받아도 될 만한 수준까지 올라왔다고 볼 수 있을 겁니다.
다만, GPT-3 small 모델은 평균 정답률이 76%로 다소 높게 나왔습니다. 기계가 썼다는 걸 대략은 알아맞힐 수 있다는 의미입니다. 정답률 50%로 낮추기 위해선, 즉 인간이 누가 썼는지 구분하기 쉽지 않은 정도의 작문 실력을 갖춘 기계를 도입하려면 적어도 GPT-3 13B(파라미터 130억개) 정도는 갖춰야 한다고 볼 수 있습니다.
뉴스 산업에서 GPT-3의 우위

GPT-3의 가장 큰 특징은 퓨샷러닝(few-shot learning)이라고 합니다. 논문 제목도 이 부분을 강조합니다. 즉 몇 개의 샘플 예제만을 보여주고, 다음 결과가 무엇인지를 예측하는 방식입니다. 제로샷러닝(zero shot learning), 원샷러닝(one shot learning), 퓨샷러닝(few shot learning) 모두 적은 추가 학습 데이터만으로 모델을 재구성하는 학습 방식인데요. 예를 들면, 제로샷 러닝은 이미 사전훈련된 모델을 해당 분야용으로 추가 학습을 시키지 않고 곧바로 적용하는 훈련 방식입니다. 그만큼 적은 데이터를 학습하는 모델이라는 의미로 보시면 될 듯합니다.
GPT-3는 퓨샷러닝에 미세조정(fine-tuning) 없이도 상당한 수준의 성능을 발휘합니다. 상당한이 아니라 일부 영역에서는 최상의 퍼포먼스를 구현하고 있습니다. 미세조정을 다시 설명해야겠죠. 일반적으로 언어모델은 사전학습을 한 뒤, 각 영역별로 별도의 추가 학습을 통한 모델의 조정 과정을 거치게 됩니다. 언어모델이 모든 영역, 예를 들어 뉴스가 될 수도 있고, 번역이 될 수도 있을 텐데요, 이런 모든 영역을 커버하기는 무리입니다. 따라서 사전 학습으로 모델의 모양을 갖춘 뒤에, 해당 분야 데이터세트를 재학습시켜서 분야 전문성을 키워나가는 방식을 취하게 됩니다. 이를 모델의 미세조정이라고 하는데요.
GPT-3는 이 과정을 걷어낼 수 있는 가능성을 제시한 것입니다. 퓨샷러닝으로 적은 수의 데이터만 학습했을 뿐이고, 게다가 모델의 미세조정까지 생략해버렸으니 기계가 그 분야에 대해 배운 것이 적을 수밖에 없을 겁니다. 그럼에도 웬만한, 아니 일부 영역에선 역대급의 성능을 발휘한다고 하니, 놀라운 성과가 아닐 수가 없는 겁니다.
이 논문이 GPT-3의 성능을 평가하기 위해 도전했던 분야는 총 9가지입니다.
- 언어모델링 : 일종의 다음 출현 단어 예측 정확도 성능 측정
- 클로즈드 북 질문에 대한 답변
- 번역
- 위그노그라드 스타일 작업
- 상식 테스트
- 독해력
- 슈퍼 글루(superGLUE)
- 자연어추론(NLI)
- 합성 및 질적 작업
GPT-3가 모든 분야에서 압도적인 성능을 발휘하진 않았습니다. 다만 이 가운데 뉴스 산업에 영향을 미칠 분야를 중심으로 소개를 해보려고 합니다.
뉴스 산업에 미치는 영향 추정
GPT-2가 발표됐을 때도 그랬지만, GPT-3 모델 또한 뉴스 산업에 보내는 신호는 명징합니다. 뻔한 뉴스는 얼마든 기계로 대체 가능하다는 것이죠. 로봇 저널리즘이 한창 논의됐을 때, 기계는 보도자료 기사 수준의 단순 보도를 담당함으로써 기자는 심층적인 뉴스에 집중할 수 있는 여유를 확보할 수 있게 될 것이라는 게 중론이었습니다. 이런 맥락에서 '진짜' 기자가 대체될 리는 없다고 저 또한 강조해왔습니다.
GPT-3는 이 명제와 전망이 여전히 유효함을 증명해주고 있습니다. 적어도 500단어 이하 평범한 단문 기사들은 인간과 기계의 경쟁 영역으로 편입되는 중이고, 비용만 저렴하다면 인간 기자를 대체할 수도 있다는 메시지입니다. 다만 GPT-3의 최상위 모델을 심층 기사의 평균 단어수인 1000단어 이상에 적용해보진 않았더군요. 이 같은 문서에까지 GPT-3가 높은 성능을 발휘하게 될지는 지금으로선 장담하긴 어렵습니다. 어쩌면 조금씩 조금씩 침투해 올 수는 있겠지만 여러 조건들이 붙게 될 것입니다.
다시 돌아가면, 짧은 단문 뉴스는 대체 가능성이 점차 높아지겠지만, 롱폼, 심층 보도물 같은 장문 기사는 여전히 저널리스트들의 영역으로 남아있고 앞으로도 남아있을 가능성이 높다고 생각합니다. GPT-3 고급 모델을 적용한 기사 작성기가 앞으로 얼마나 낮은 비용으로 시장에 소개될지는 모르겠지만, 단순한 단문 기사가 인간 기자의 영역에서 여전히 잔존하게 될 것이라는 믿음은 내려놓는 것이 좋겠다는 생각입니다. 언론사는 심층 기사를 작성할 수 있는 기자들에게 더 투자하는 것이 장기 전략 측면에선 불가피할 듯합니다.
공유 데이터저장소로서 커먼 크롤의 기여
저는 이 모델의 탄생을 위해 어떤 데이터를 학습했느냐, 즉 입력값을 어디서 구했느냐에 관심이 많았습니다. 학습한 데이터의 성격에 따라 해당 알고리즘이나 모델의 편향 정도가 달라질 수도 있기 때문입니다. 학습 대상으로서의 데이터세트는 그래서 관찰하고 분석할 가치가 있다고 생각합니다.
이 논문은 학습 데이터로 커먼 크롤(common crawl) 데이터세트를 비롯해 웹텍스트, 인터넷 기반의 책 코퍼스 1, 2권, 위키피디아 등이었습니다. 이 가운데 가장 비중이 높았던 학습 데이터는 커먼 크롤의 텍스트 데이터였습니다. 토큰수로만 따지면 무려 4100억개라고 합니다. 어마어마한 양의 텍스트 데이터를 모델 구성을 위해 활용했다는 것입니다.
커먼 크롤은 커먼 크롤 재단이 수집해서 운영하는 데이터 저장소입니다. 누구가 사용할 수 있는 커먼스의 영역 즉 공유지 영역입니다. 이들이 선언하고 있다시피 "Our goal is to democratize the data so everyone" 즉 특정 기업을 위해서가 아니라 모두가 데이터를 활용할 수 있도록 돕는, 데이터 민주화를 목표로 삼고 있습니다. 그래서 비영리 조직입니다.
GPT-3가 탄생할 수 있으려면, 결국 이러한 거대한 데이터 공유지가 존재해야만 합니다. 그러지 않고서는 학습할 수 있는 데이터를 구하기가 정말 어렵습니다. 데이터를 수집하는데만 상당한 시간이 소요될 것이고 비용도 천문학적일 겁니다. 심지어 이 데이터를 저장하는 스토리지도 아마존이 지원을 하고 있습니다.
한국의 현실을 돌아볼까요? 막상 한국어를 대상으로 GPT-3, BERT와 같은 언어모델을 만든다고 가정해보면, 1차 Pre-Training 데이터를 어디서 구할 수 있을까요? 다들 저작권에 묶여 있고 그때마다 소송에 대비해야 한다면 누구도 더 나은 언어모델을 만들기 위해 노력하기가 쉽지 않을 겁니다. 대규모의 데이터세트를 보유하고 있는 일부 대형 IT이 아니라면 개인 개발자, 연구자들이 시도조차 하지 못할 겁니다.
아쉽게도 커먼 크롤에는 한국어 데이터세트가 포함돼 있지 않습니다. 그나마 위안이라면 ETRI의 한국어 말뭉치 데이터세트에 접근할 수 있다는 겁니다. 여긴엔 한국어BERT 언어모델도 사용할 수 있도록 배려하고 있습니다. 공공 연구기관의 이러한 노력조차 없었다면 국내 언어모델의 향상은 대기업 위주로만 진행됐을 가능성이 크지 않았을까요?
더 나은 언어모델과 뉴스 산업의 협업
언어모델의 성능 향상을 두려움의 관점을 접근할 이유는 없다고 봅니다. 여전히 인간과 기계의 영역 구분은 명확하고, 대체 불가능한 직업군으로서 저널리스트들의 역할은 바뀌지 않을 것이라고 생각합니다. GPT-3는 퓨샷러닝 기반의 미세조정 없는 언어모델만으로도 충분히 좋은 결과를 낼 수 있다는 걸 세상에 알렸습니다. 한국어 언어모델로 전환돼 현장에 적용하기까지는 적지 않은 시간이 걸리겠지만, 그런 노력들은 오히려 언론산업을 더욱 유망한 분야로 인식시키는데 도움을 줄 것이라고 생각합니다. 언론산업에 개발자들이 뛰어들면 전망이 없을 것이라는 인식도 불식될 수 있다고 봅니다. 결국 이 분야에 과감한 투자를 할 수 있는 언론사만이 그 영광을 취할 수 있지 않을까 합니다.