
자동팩트체킹 기술의 흐름과 한국 언론계의 과제
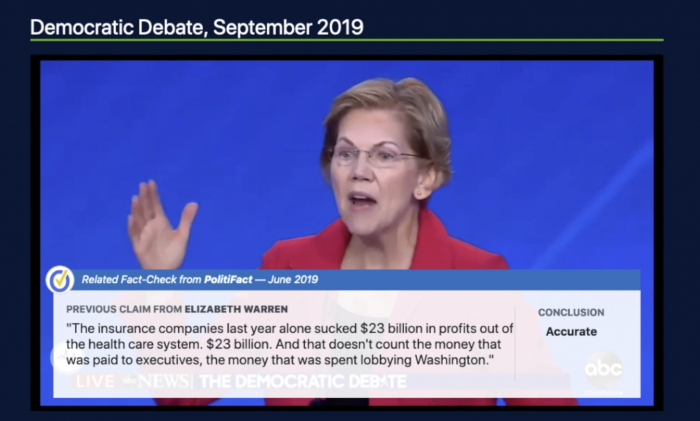
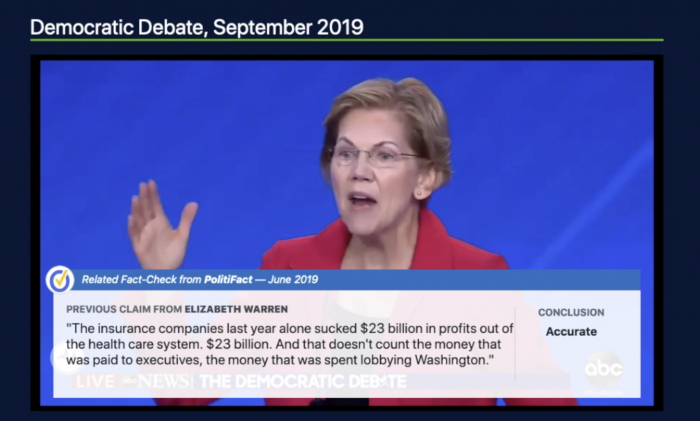
자동팩트체킹 기술에 대한 관심이 높아지고 있습니다. 얼마전 정부가 발표한 미디어 소통 역량 강화 종합 계획에도 이 프로젝트는 포함돼 있었죠. 새로 시작하는 사업이어서가 아니라 이미 진행되고 있는 사업이기에 새롭다고 볼 순 없을 겁니다. 하지만 정부가 허위조작정보에 대응하기 위해 관심을 기울이고 있는 영역이라는 사실만큼은 분명해 보이긴 합니다.
자동팩트체킹 기술에 대한 높은 기대는 날로 증가하는 허위조작정보의 양에 비례한다고 저는 생각합니다. 인간 팩트체커의 힘만으로는 폭증하는 허위조작정보를 모두 검증할 수도 그렇다고 속도를 제어할 수도 없기 때문이죠. 수용자 입장에서도 검증되지 않은 정보들이 인터넷 곳곳으로 퍼져나가면서 부지불식간 믿게 되고 재유통시키는 우를 범할 확률도 높아지고 있습니다. 자동팩트체킹 기술에 대한 수요가 늘어나는 배경일 겁니다.
포인터 연구소에 따르면 현재 자동팩트체킹 기술은 크게 2가지 방향으로 개발되고 있다고 합니다. 과거 팩트체킹 DB나 출처 기반으로 검증하는 기술과 입장 탐지(stance detection) 기술이 그것입니다.
팩트체크 DB 대조 기술
전자에 대해서는 그렇게 길게 설명드리지 않아도 될 듯합니다. 그래서 짧게 소개하자면, 기 검증된 팩트체크 DB를 활용하는 방식입니다. 우선 전세계 팩트체커들이 검증한 팩트체크들을 구조화된 데이터로 저장하거나 확보를 합니다.이미 이렇게 모아진 거대한 DB가 공유되고 있다는 사실을 들어보셨을 겁니다. 주로 영문으로 작성돼 있긴 하죠.
DB 대조형 자동팩트체킹 기술은 새롭게 제기된 주장 진술문이 과거에 팩트체크된 것들과 비교해 사실 여부를 판정합니다. 팩트체킹 DB가 많을수록 빠르게 판정할 수 있는 확률이 높아지겠죠. 여기에 신뢰할 수 있는 통계나 기타 근거 자료들도 동원합니다. 과거 팩트체크 DB에 포함돼 있지 않은 진술문을 판별하려면 추가적인 데이터가 반드시 필요하기 때문입니다.
이렇게 개발된 대표적인 자동팩트체킹 기술은 다음과 같습니다.
- 듀크 대학의 스쿼시(Squash)
- 영국 풀팩트의 자동팩트체킹
- 아르헨티나 체케아도의 체케아봇
- IFCN의 챗봇
이미 짐작하셨겠지만, DB 대조형 자동팩트체킹은 사람의 개입이 생각보다 많이 들어갑니다. 스쿼시만 하더라도 최종적으로 방송 등으로 내보낼지 여부는 인간이 결정하도록 구성돼 있습니다. 정확성의 빈틈이 여전히 존재하기에 조심스러울 수밖에 없죠.
입장 탐지 기술
입장 탐지 기술은 진술문과 기사의 쌍을 기계에 학습시켜서 의심스러운 진술을 찾아내는 방식입니다. 이를 위해 주로 사전학습된 언어모델(Language Model)을 활용합니다.
먼저 입장 탐지 중심의 자동팩트체킹 기술의 프로세스를 들여다 볼 필요가 있습니다. 워털루대 발표한 논문에 따르면 다음과 같이 구성이 된다고 합니다.
- 문서 검색(Document retrieval) : 여러 출처에서 해당 진술과 관련된 기사들을 수집
- 입장 탐지(Stance detection) : 진술과 관련된 기사의 입장 / 위치 확인
- 평판 평가(Reputation assessment) : 언어와 출처 분석으로 신뢰성 결정
- 진술 검증(Claim verification) : 입장과 평판을 결합해 진실성 결정
우선 입장 탐지 기술과 관련해서 워털루대의 판별 모델을 중심으로 조금더 들여다보도록 하겠습니다. 워털루대의 연구를 보면, 기사와 진술 쌍으로 구성된 데이터를 RoBERT 모델로 학습을 시킵니다. 이 데이터는 토우 센터가 개발한 Emergent라는 루머 추적기에서 받아왔습니다. 이렇게 모아진 데이터를 학습한 뒤에 그 결과를 4개의 라벨로 구분을 하게 됩니다.
- 동의 : 기사가 진술에 동의를 할 경우
- 부동의 : 기사가 진술에 부동의 할 경우
- 논의 : 기사와 진술이 관련은 있지만 글쓴이의 입장이 없는 경우
- 무관함 : 기사와 진술이 관련이 없을 경우
결과도 우수했다고 합니다. 2017년에 Fake News Challenge라는 대회가 있었는데요. 여기서 상위 3위에 랭크된 방법론들보다 정확도에서 더 높은 점수를 얻었다고 합니다. 물론 이 방법이 이 대회에 참여했던 것은 아니고요. 언어 모델로 접근했을 때 더 높은 정확도와 낮은 에러율을 가져올 수 있다는 가능성을 확인한 것이죠.

한국 언론계와 팩트체커들에 주는 메시지
위 두 가지 자동팩트체킹 기술은 방대한 데이터베이스 세트에 의존하고 있다는 걸 확인할 수 있습니다. 듀크대의 스쿼시는 누적된 ClaimReview 데이터베이스가 없었다면 구축하기 쉽지 않았을 겁니다. 스쿼시를 개발한 듀크대 쪽의 이야기를 들어볼까요?
“하지만 이를 가능하게 하기 위해, 우리는 ClaimReview 데이터베이스 수천 개의 팩트체크에 주제 태그를 붙여야 했습니다. 이를 위해 Guess는 Caucus라는 게임을 만들었습니다. 휴대폰에 팩트체크를 표시한 다음 거기에 주제 태그를 할당해 달라고 요청하는 형태입니다.”
데이터커먼스를 통해 확보한 크레임리뷰에 추가로 주제 태그를 붙여서 스쿼시를 개발하고 있다는 겁니다.
워털루대의 자동팩트체킹은 현재는 지속되고 있지 않은 토우센터의 ‘Emergent Project’의 데이터 세트로 개발했습니다. ‘기사와 진술문’ 쌍 7만여 데이터 세트 중에 49,972개를 트레이닝 세트로, 25,413쌍은 테스트 세트로 활용해 개발한 겁니다. 현재 이 프로젝트는 더이상 운영되고 있지는 않습니다.
아시다시피 국내 언론사 중에 크레임리뷰를 적극적으로 마킹하는 곳은 거의 없습니다. 자동팩트체킹 기술을 개발한다고 하더라도 결국엔 구조화된 팩트체킹 기사 데이터에 의존해야 하는데 그 기반이 너무 취약하다는 거죠. 그나마 희망이라면 SNU FactCheck센터가 보유한 팩트체크 데이터베이스입니다. 다만 아쉬운 점은 센터가 보유한 양도 생각만큼 많지 않다는 사실입니다. 특히 언어모델 기반으로 자동팩트체킹을 개발해야 한다고 가정하면 절대적으로 부족하다고 볼 수 있을 겁니다.
경험치로 판단해 보건대, 국내 팩트체커들 중에서 팩트체크 기사의 구조화된 데이터화와 그것의 가치에 대해 깊은 이해와 식견을 지닌 분들이 많지는 않았습니다. 이미 제안된 크레임리뷰 마크업이 아니더라도 팩트체크 기사의 차별적 특성을 기계이해 가능한(machine readable) 방식으로 공동 데이터베이스화하는 작업은 자동팩트체킹 개발에 필수적일 겁니다. 결국 팩트체커 스스로가 쌓아둔 DB는 자신의 팩트체킹 역량을 증강시키는데 반드시 도움이 될 겁니다.
지난 8월말 발표한 정부의 미디어 소통역량 강화 종합계획에도 자동팩트체킹 툴 개발이 포함돼 있었죠. 현재 이 기술을 개발하는 곳이 있는 것으로도 알고 있습니다. 국내에서도 이러한 기술의 도움을 얻고자 한다면, 국내 팩트체커들이 그들 자신의 작업물을 잘 구조화해두는 것, 특히 그것이 공유화한 자원으로 풀릴 때 훨씬 더 큰 역량을 발휘한다는 걸 인식해주시면 좋겠습니다.
